
1. What is vector database?
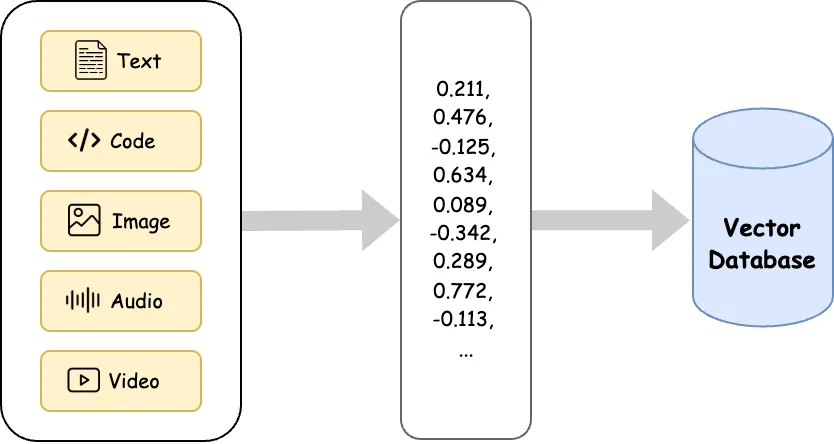
A vector database is a type of database optimized to store, index, and search high-dimensional vectors, which are typically used to represent unstructured data like text, images, audio, and video.
A vector database stores data entries as records with the following main components:
- ID: primary key. E.g. “doc_1234”
- Vector: the main feature, a high-dimensional float array representing the data. E.g. [0.12, -0.45, 0.33, …, 0.98]
- Metadata: optional, it is used for tags or attributes. E.g.
{
"type": "support_doc",
"language": "en",
"created_at": "2025-01-01"
}
Here is the sample record in a vector database:
{
"id": "doc_1234",
"vector": [0.12, -0.45, 0.33, ..., 0.98],
"metadata": {
"category": "account",
"language": "en",
"priority": "high"
}
}
2. Vector database applications
Here are some popular applications of Vector DB:
2.1. Semantic search
Keyword search is too literal. Vector DB supports to find the results that are semantically similar.
E.g. A user goes to a company’s help center and types: “I can’t get into my account”. Traditional keyword search might fail because it just looks for the documents with matching keywords (“can’t”, “account”). It will miss the helpful articles like:
– “How to reset your password”
– “Fix login issues”
…
2.2. Embeddings from ML models
Models like OpenAI, Cohere, and CLIP convert text/images to vectors. We need a place to store and search those vectors.
2.3. Fast similarity search
Comparing 1 vector against millions is very slow with brute force. Vector DB use optimized indexes (HNSW, IVF) to make it fast.
E.g. Recommend similar songs from a database of 1M audio clips.
2.4. Building LLM based apps
Large Language Models (like GPT-4) don’t know your data. Vector DB is used to enable semantic retrieval of relevant context that the language model (LLM) can use to generate accurate, grounded, and useful response.
E.g. A legal chatbot retrieves case law snippets to help answer questions.
2.5. Personalization or recommendations
Match users with similar behaviors, preferences, or content.
3. Retrieval Augmented Generation
A typical traditional system may include:
- A relational DB (e.g., MySQL, PostgreSQL)
- Admin dashboard or website
- REST APIs
- Keyword search, form input,…
3.1. What is the enhancement of the Vector Database?
| Traditional Component | Vector DB Enhancement Example |
|---|---|
| 🔍 Keyword Search | Add semantic search for queries |
| 📦 Product Catalog | Recommend similar products using product descriptions |
| 📚 FAQ or Document Center | Retrieve relevant documents by meaning, not keywords |
| 👤 CRM or Helpdesk | Auto-suggest replies based on semantic case history |
| 🛒 E-commerce | Suggestions based on vector similarity |
| 🧾 SQL Database | Store metadata or primary data in Postgres + use vector DB for similarity search |
3.2. How to integrate Vector Database into a traditional system?
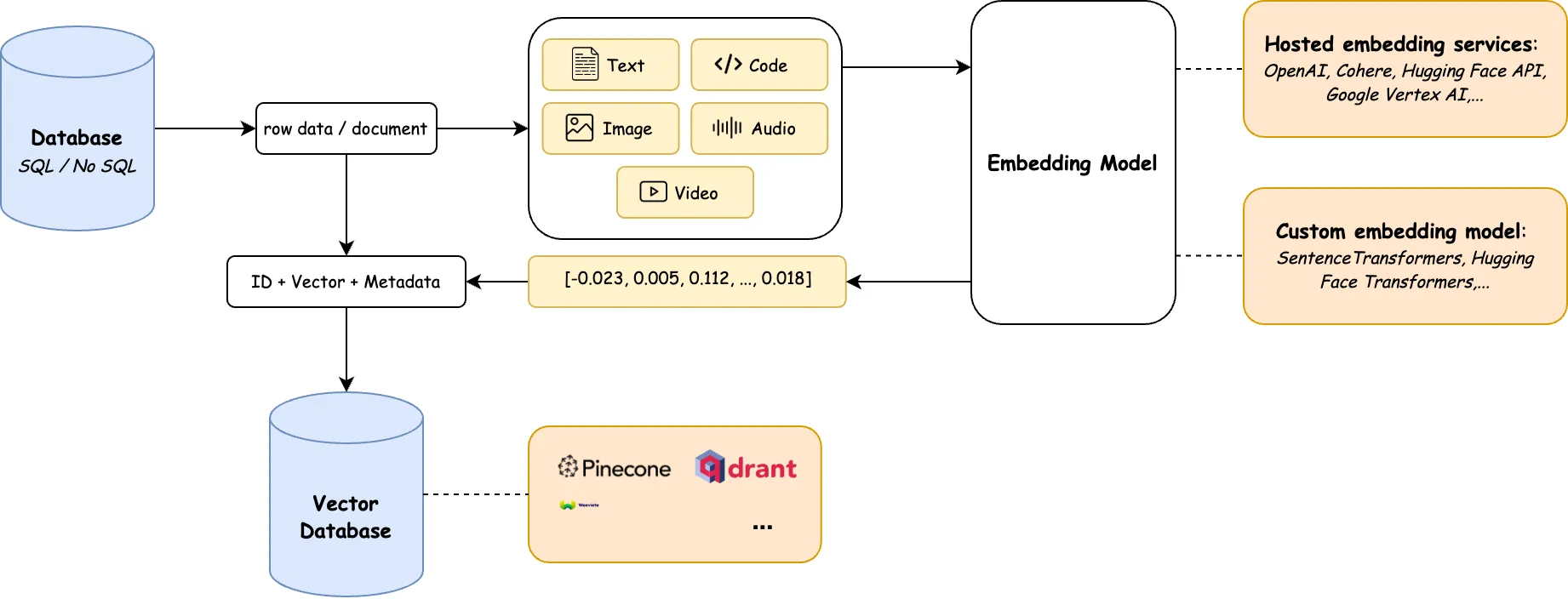
- Embedding model:
- Hosted Embedding Services (API-based): OpenAI, Cohere Embed API, Google Vertex AI Embedding, AWS Bedrock / SageMaker, Azure OpenAI,… You send input text or code to their API and get back a vector embedding.
- Custom (Self-Hosted) Embedding Models: SentenceTransformers, BGE, CodeBERT, CodeT5,…In this approach, you run an embedding model on your own infrastructure.
- Generate vector embeddings: Use a model like OpenAI’s text-embedding-ada-002 to convert text into vectors. Some common embedding model input types: text (text-embedding-ada-002, sentence-transformers), images (CLIP, OpenCLIP, ResNet, DINO, BLIP), audio (Whisper, Wav2Vec2, AudioCLIP), video (VideoCLIP, XCLIP, TimeSformer), code (CodeBERT, GraphCodeBERT).
- Vector Database: The traditional database holds your structured business data (rows, columns), while the vector database holds the semantic representation (vectors) of selected fields (e.g., descriptions, documents, images).
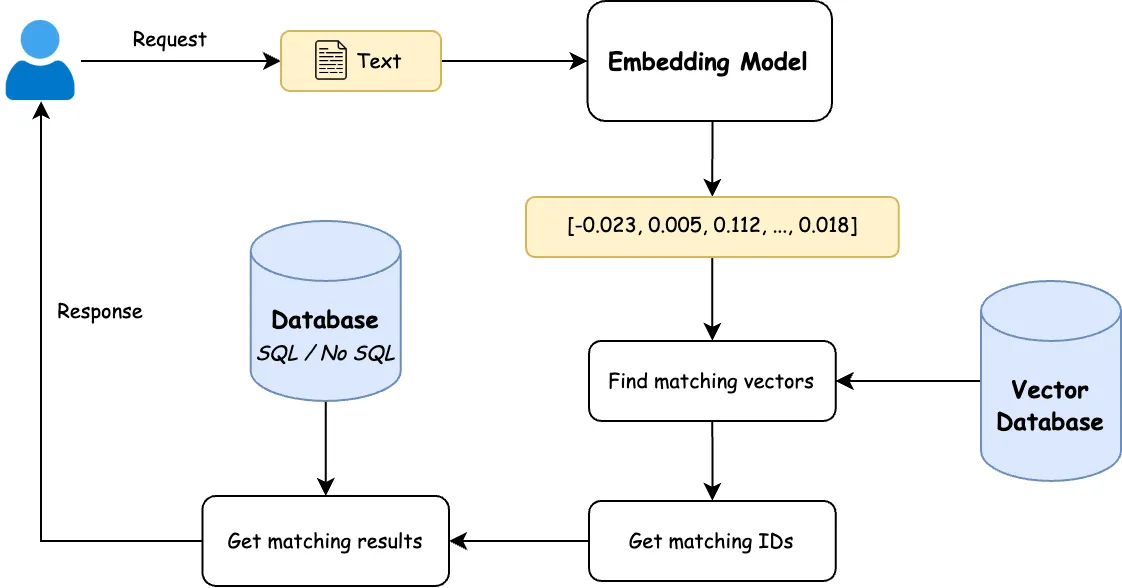
- User enters a natural language query, this is just a text input and we want to search by meaning, not exact words.
- Use an embedding model to convert the query into a vector.
- Query the vector DB to find the top K nearest vectors (ANN search).
- Use those IDs to get the actual data from traditional DB.
- Return the most relevant items to the user.
3.3. Some main features
| # | Feature | Description | Example / Use Case |
|---|---|---|---|
| 1 | Semantic Similarity Search | Retrieve results based on meaning, not exact keywords. | Input: “healthy fruit” => Output: “red apple”, “cherry juice” |
| 2 | K-Nearest Neighbors (k-NN) / ANN Search | Find the top K most similar vectors using cosine similarity or dot product. | Top product matches, similar documents, related user profiles |
| 3 | Personalized recommendations | Recommend items close in vector space to user preferences. | Based on: user behavior, product likes, past interactions. |
| 4 | Contextual Retrieval (RAG for LLMs) | Retrieve relevant vectors to provide context for a language model. | Used in: AI chatbots, document Q&A, internal knowledge assistants |